Issue 67: LPWG Occurrence data working group
Assembling a global, expert-verified species occurrence dataset for family Leguminosae
Coordinators:
Edeline Gagnon (Royal Botanic Garden, Edinburgh, U.K.)
Joe Miller (Global Biodiversity Information Facility, GBIF, Denmark)
The central goal of the Legume Occurrence Working Group is to produce an expert-verified, global occurrence dataset for the entire legume family. As legumes are economically and ecologically important, such a dataset would find many uses among ecologists, evolutionary biologists, conservationists, plant breeders, foresters and others. To ensure data reproducibility, we focus primarily on preserved specimens from herbaria, although other records that are verifiable are also being considered.
While it is now extremely easy to download data from global occurrence databases such as GBIF and use standard cleaning tools, custom-made R scripts and OpenRefine to edit the data, there are still a number of important bottlenecks to assembling high-quality occurrence data, including:
- Having an up-to-date and accurate list of accepted names and synonyms for all legumes;
- Verifying the taxonomic identity of occurrence records;
- Assessing whether the final set of occurrence records for any given species accurately represents the known geographic distribution.
Our strategy is to overcome these difficulties by:
- Having an up-to-date and accurate list of accepted names and synonyms for all legumes;
- Verifying the taxonomic identity of occurrence records;
- Assessing whether the final set of occurrence records for any given species accurately represents the known geographic distribution. Our strategy is to overcome these difficulties by:
We expect different occurrence datasets will present different challenges (e.g. additional geo-referencing, use of different databases depending on geographic regions, how to identify non-native records) and will require different cleaning strategies. All data will be required to meet minimum standards based on specified guidelines and tools, while some users will clean and explore their data further if they wish. Each dataset would generate a micro-publication including the methods and tools they used, and an assessment of data quality and completeness. Furthermore, micro-publications, with associated DOIs would make the work citable providing recognition for this type of work.
Pending completion of the Legume Taxonomy WG checklist the Occurrence Working Group has:
- Compiled a list of current and on-going efforts to assemble and georeference occurrence record data. Our survey indicates that while considerable efforts have been made for certain subfamilies, significant challenges remain for amassing data for subfamily Papilionoideae, in which most legume species diversity is concentrated.
- Produced a series of R scripts for (i) retrieval of GBIF data based on a list of accepted names and synonyms; (ii) cleaning of the retrieved occurrence data, based on the framework of the script from Ringelberg et al. (2020), modified to add tools from the R Package “CoordinateCleaner” (Zizka et al. 2019), plus additional custom scripts provided by E. Gagnon and Y. Barros Souza. These scripts will be made available shortly through GitHub.
During 2021 we plan to organize a meeting to present and discuss the proposed work- flow and R scripts for retrieval of data directly from GBIF and standard cleaning tools. In addition, updates are expected about new GBIF-hosted data cleaning tools and occurrence data indexing to an updated taxonomy that includes many recommendations from the legume taxonomic working group. We are also planning a brainstorming meeting to explore ideas for using the new expert-verified global legume occurrence data in legume biogeography. Further details about these meetings will be available shortly. Finally, once the species checklist is available, we plan to move forward with legume-wide data cleaning.
New community developed best practices document in georeferencing have been published by GBIF. This set of three guides provide theory, methods and advice on spatial interpretation of locations. If you are interested in participating in our group, or have questions, please contact edeline.gagnon@gmail.com or jmiller@gbif.org. We are keen to hear from everyone working to expand and improve the quality of available legume occurrence data.
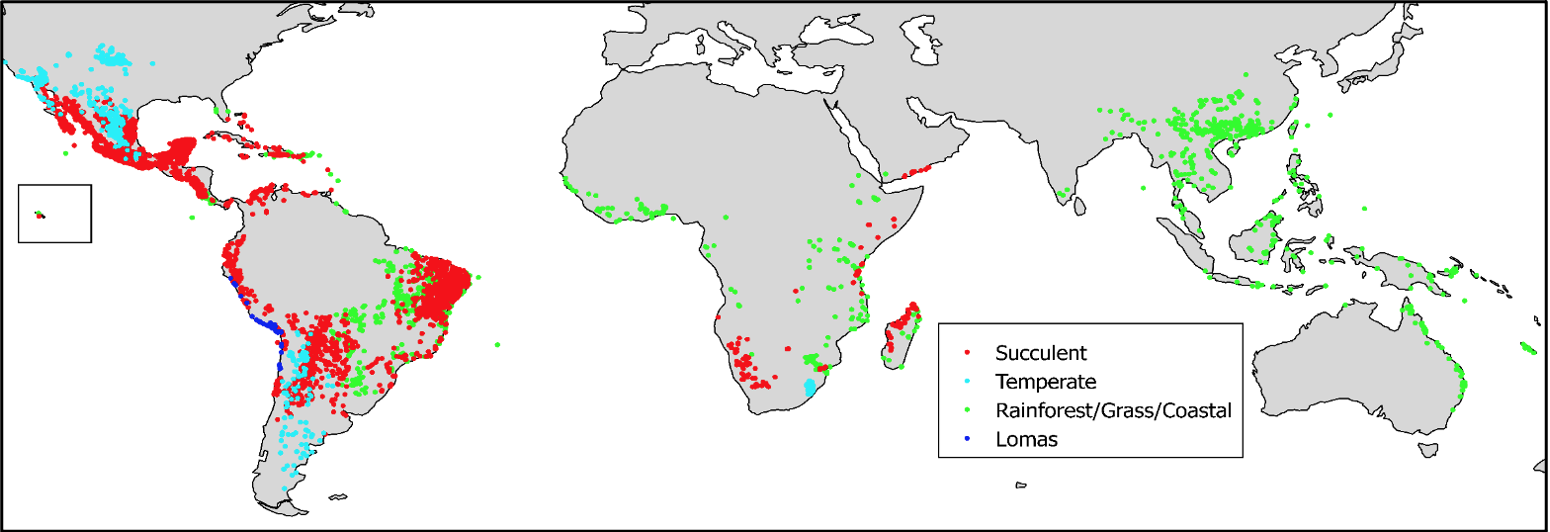
Exemplar data set used to map the distribution of the Caesalpinia Group based on 17,260 quality-controlled occurrence records. From Gagnon, E. et al. 2019. New Phytologist, 222: 1994- 2008.
References:
Ringelberg, J.J., Zimmermann, N.E., Weeks, A., Lavin, M. & Hughes, CE. 2020. Biomes as evolutionary arenas: conver gence and conservatism in the trans-continental Succulent Biome. Global Ecology and Biogeography 29: 1100-1113. https://doi.org/10.1111/geb.13089
Zizka, A., Silvestro, D., Andermann, T., et al. 2019. CoordinateCleaner: Standardized cleaning of occurrence records from biological collection databases. Methods in Ecology and Evolution 10: 744– 751. https://doi.org/10.1111/2041-210X.13152